データ構造と
メソッドのネーミング
データ構造など技術的な背景をちゃんと知っていれば、データ操作に関する正しい英語を使えるねーて話です。用語のイメージもつかめるようにしていますので、shift / unshift とかイメージできない方もどうぞ。
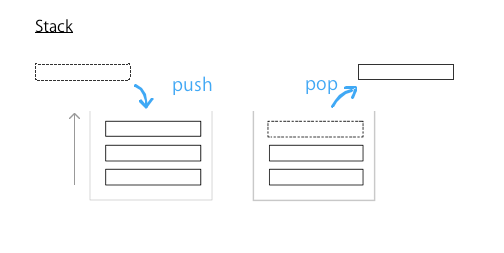
1. push / pop = スタック
push pop は、スタックの用語で、それぞれ pop はスタックから取り出す、push は挿入する事を意味します。JavaScript や Ruby の Array には、スタックとしてのコンセプトもあるので、push / popという用語が使われます。
対して、Javaの ArrayList (インターフェースは Collection) は、単なる集合を表すインターフェースなので、抽象化のために add / remove というネーミングが使われます。そういえば、Javaには、Stackというクラスも別途用意されていますね。Stackクラスでは、push / pop が使われています。
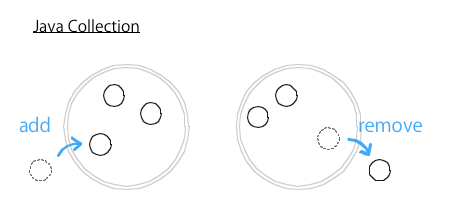
addは末尾に追加する?
余談ですが、Java使いの人の中には、addというネーミングが末尾に追加するとイメージしている人もいるかもしれません。実は、addという単語には末尾に追加するというニュアンスは厳密にはありません。それは、ArrayList の実装がそうなっているだけです。
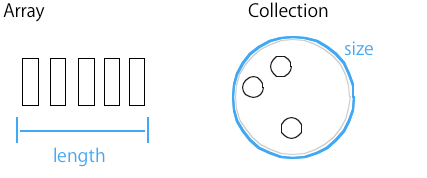
2. length = 配列
length は、配列 (Array) でよく使われる単語です。それは、直線上に並んでいる場合のみ Length = 個数となるからです。並んでいなければ、長さを調べても仕方ないですからね。なので、Java の Collection は、直接上にならんでいるわけではないので、size という抽象的な単語が使われています。.NET FrameworkのIListインターフェースは Countですね。これも同じ理由です。
_
_
Ruby では、size / length どちらでも使えるみたいですね。きっと、文脈に合わせて使い分けできるようになっているんだと思います(きっと)。
3. shift / unshift = ビット列、配列
shift, unshift は、元々ビット列操作の用語ですが、配列 (Array) でも使われています。当然 JavaのCollection は、配列ではないので shift や unshift はありません。shift は 先頭側へ unshift は後方側へ配列の要素をずらします。
_
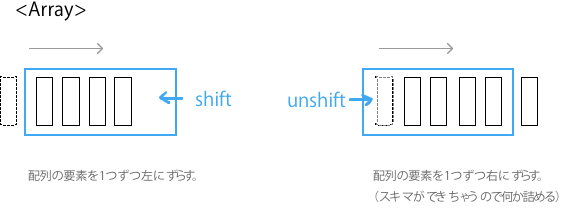
unshiftのイメージ
unshift は先頭に追加する操作なのですが、”先頭に要素を追加する” と覚えてしまうのとイメージしにくいので、”配列の要素を右にずらして、隙間ができちゃうので何か詰める” と覚えると、イメージしやすいと思います。
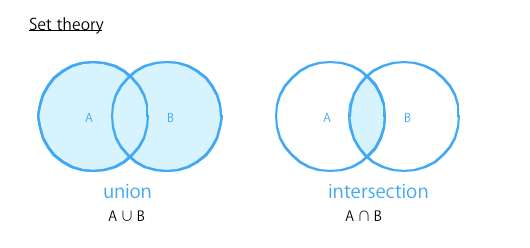
4. union / intersection = 集合
SQLとかで出てくるヤツで、union や intersection (intersect) は、それぞれ和集合、差集合積集合を意味する集合論 (set theory) の用語です (Cの共用体は別)。よくベン図とかで見るあれです。集合論の用語なので、対象は Collectionや配列に限定されます。
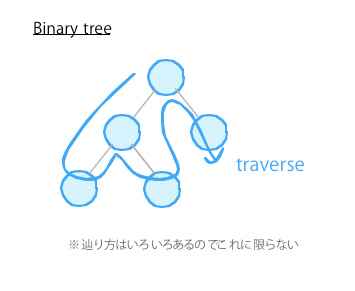
5. traverse = 木構造
ツリー(木構造)の用語で、ノードを全て辿ることを意味します。ツリーの用語は、DOMやネットワークなんかでよく見ますね。ツリーの用語には、node, leaf, root, parent などたくさんあるので、ツリーの方法論に帰納すると抽象化し易かったり、ネーミングが楽になりますね。
6. parse = 言語学
言語学の用語です。parse は、構文(syntax) を分析することを意味します。みなさんがよく知っているプログラミング言語も、構文を持っているので、parse される対象になります。parse という単語が使えるかどうかは、対象が構文を持っているかによります。
7. まとめ
適切な単語を選ぶには、英語力だけでなく技術的な背景や用語を知る事も必要、みたいな事ですかね。add / remove みたいなちょっとした単語の選択でも差が出たりしますので、たまには、標準ライブラリの何気ないネーミングがなぜそうなっているか調べてみると、ボキャブラリー強化に繋がるかもしれませんよ^。
– 追記 : コメントで指摘を頂き intersect を intersection に修正しました。

Kenji in codic
codic のリードプログラマー / デザイナーです。時間があれば、英語やネーミング、NLPについて研究したりしています。